实验 1 - 搭建 Hadoop 环境¶
前置条件¶
| 项目 | 最低配置 | 推荐配置 |
|---|---|---|
| 存储 | 10 GB HDD | 20 GB SSD |
| 内存 | 8 GB DDR3 | 16 GB DDR4 |
| 处理器核心数 | 2 | ≥ 4 |
| 处理器架构 | Sandy Bridge / K10 | Skylake / Zen / ARMv8 |
| 处理器指令集 | 无虚拟化扩展 | VT-x / AMD-V / ARMv8 VMID |
这些条件非硬性要求,在不满足若干个上述条件的情况下仍可继续完成本系列实验。
概述¶
本次实验的目的是得到一个搭建好且可以正常运行的 Hadoop 环境。我们的原则是:
- 同时支持 Windows、macOS 和 Linux
- 尽可能使用现代化,非过时的技术栈/软件版本
- 尽可能按照行业最佳实践操作
- 尽可能在配置层面1与原始 CentOS 版本保持一致
使用的软件:
- 虚拟机工具
- 操作系统:Ubuntu Server 22.04.5 LTS
- Hadoop:Hadoop 3.3.6
注意!
你不需要下载全部虚拟机工具,请根据你使用的系统选择。所有和主机操作系统有关的下载项前均有对应的图标。
刚买了 MacBook?
没关系,在 M 家族 Apple 芯片的 Mac 设备或其它 ARM 架构的设备上(如 Surface Pro X),此教程无法完全适用,但技术上运行 Hadoop 是完全可行的,可以尝试。况且 Hadoop 3.3.6 还增加了原生 ARMv8 支持呢。
有问题?
我们为你总结了一系列在本实验中可能遇到的常见问题,你可以在目录中找到。
下载需要的软件¶
虚拟化软件¶
曾经安装过虚拟化软件?
如果你已经安装并配置好了虚拟机软件,可以直接跳过这个小段的下载。
-
如果你正在使用 Windows,你有多个选择2:
- VMware Workstation Pro 17: 官方地址
- VirtualBox: 清华大学开源软件镜像
- QEMU
- Hyper-V
关于VMware Workstation Pro 激活
2024年5月14日,博通宣布 VMware Workstation Pro 改为个人免费使用,并宣布 VMware Workstation Player 停产。 2024年11月13日,博通宣布 VMware Workstation Pro 改为全面免费使用,包括企业和个人用户。 所以请放心的使用吧!
-
如果你正在使用 macOS,你有多个选择:
- VMware Fusion Pro:
- VirtualBox:
- 清华大学开源软件镜像
- 如果你的 macOS 版本是 High Sierra(10.13)或更新,并且已经安装了 Homebrew ,你可以使用以下命令来快速安装:
- 如果你正在使用 Linux:
- VirtualBox: 官方文档
软件镜像¶
- 系统镜像: Ubuntu Server 22.04 LTS (x86-64): 清华大学开源软件镜像
- Hadoop: Hadoop 3.3.6: 清华大学开源软件镜像
如果你是使用 M 家族 Apple 芯片的 Mac,Surface Pro X 等 ARM 设备
尝试以下组合:
- 系统镜像: Ubuntu Server 22.04 LTS (ARM64): 清华大学开源软件镜像
- Hadoop: Hadoop 3.3.6 for AArch64: 清华大学开源软件镜像
配置虚拟机¶
创建虚拟机¶
跟随对应的虚拟机软件中的菜单,新建一个虚拟机,除非特别说明,否则均可以使用默认配置。
选择镜像¶
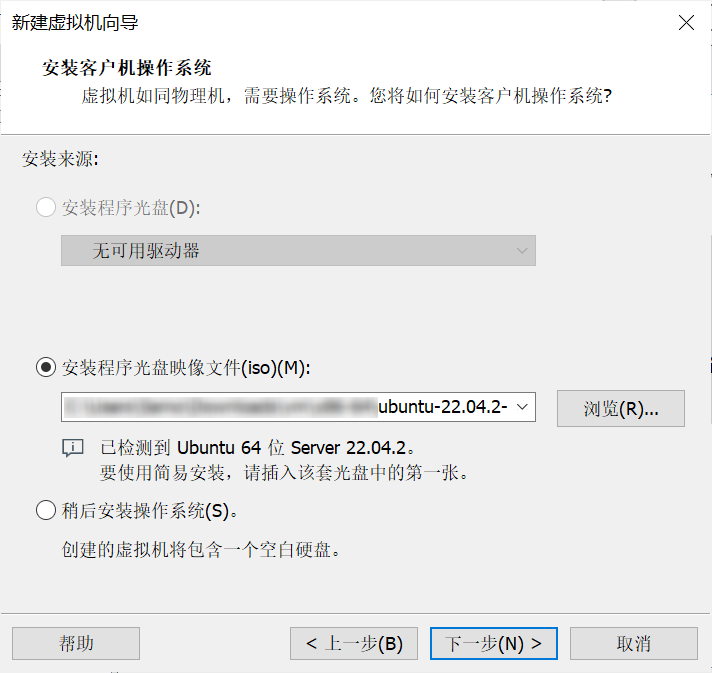
选中下载的镜像后(文件名应为 ubuntu-22.04.5-live-server-amd64.iso),进行下一步。
VMware 用户提示
如果你使用 VMware 系列软件,在被提示到“使用简易安装”时,请务必关闭该功能(取消勾选)。简易安装主要适用于带图形界面的桌面版 Ubuntu 操作系统,在我们使用的服务器版 Ubuntu 中可能导致问题。
BIOS/UEFI 启动

如果被问及是使用 BIOS 还是 UEFI 启动,请选择“传统 BIOS”
UEFI 是更加现代化的操作系统引导机制,由 Intel 提出,但同时 UEFI 也会引入更多复杂情况。为了保持流程简单,继续使用传统 BIOS 启动。
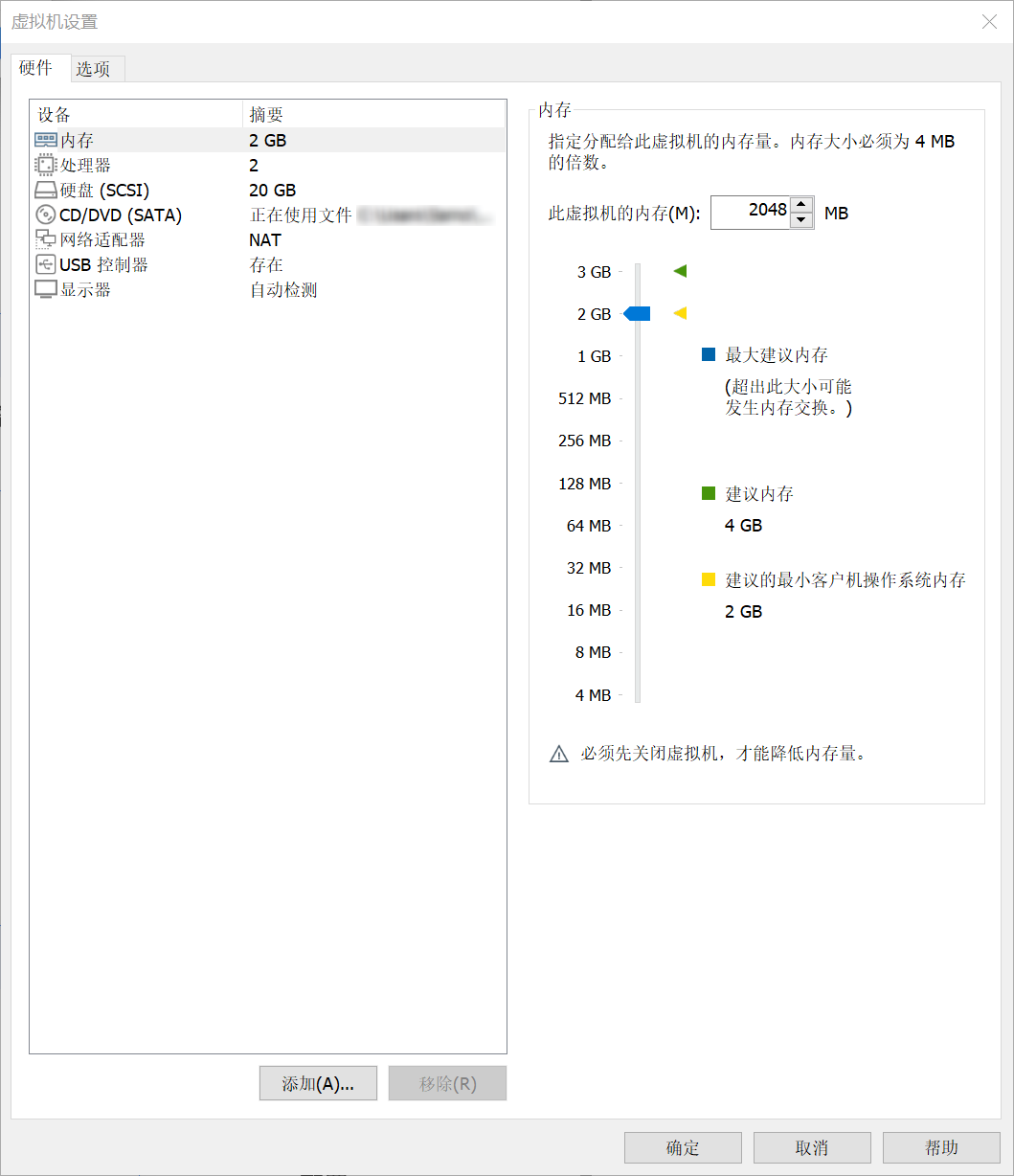
硬件配置¶
完成后,建议将硬件调整为以下配置:
| 项目 | 配置 |
|---|---|
| CPU | 2 核心 |
| 内存 | 2 GB / 2048 MiB |
| 硬盘 | 20 GB,多文件3 |
| 网络 | NAT |
CPU 设置的细节
如果你使用的是 VMware Workstation Pro,请记得在设置处理器核心数量时,设置为处理器数量为 1、每个处理器的内核数量为 2.
提高性能!
可以移除虚拟机默认添加的,不需要使用的硬件来部分减轻负载。以下设备可以安全移除:
- 打印机
- 摄像头
- 声卡
推荐的配置如下图所示:
安装操作系统¶
语言设置¶
将虚拟机开机,等待启动完成,进入设置向导。
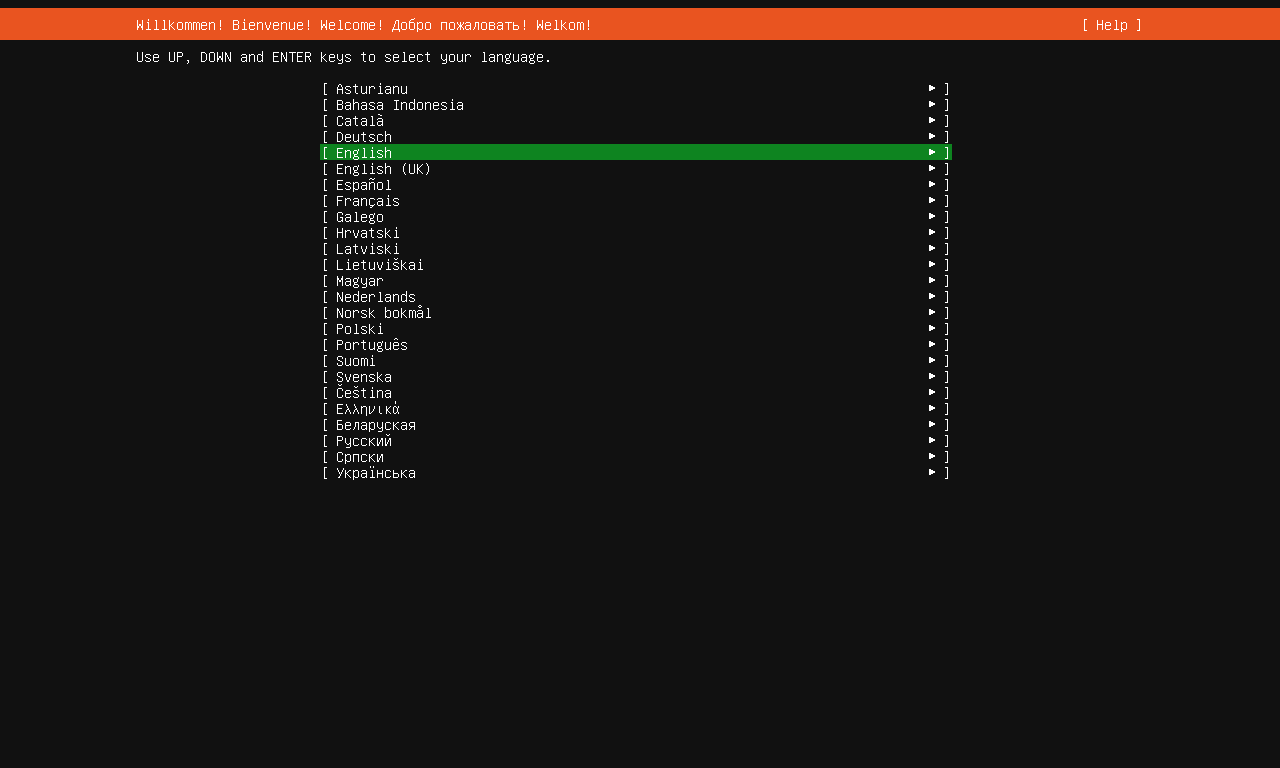
在这里直接选择默认的 English,按下回车键继续。在下一页中,保持默认键盘布局设置,回车继续。
为什么不用中文?
中文字符集相对复杂,依然建议使用字符集简单的英语为操作系统语言,否则容易出现 TTY 乱码或显示豆腐字(◻︎)问题。在 VESA VGA 模式下,默认色深只能显示 256 个字符。
真的,不是什么东西都能设置成中文的
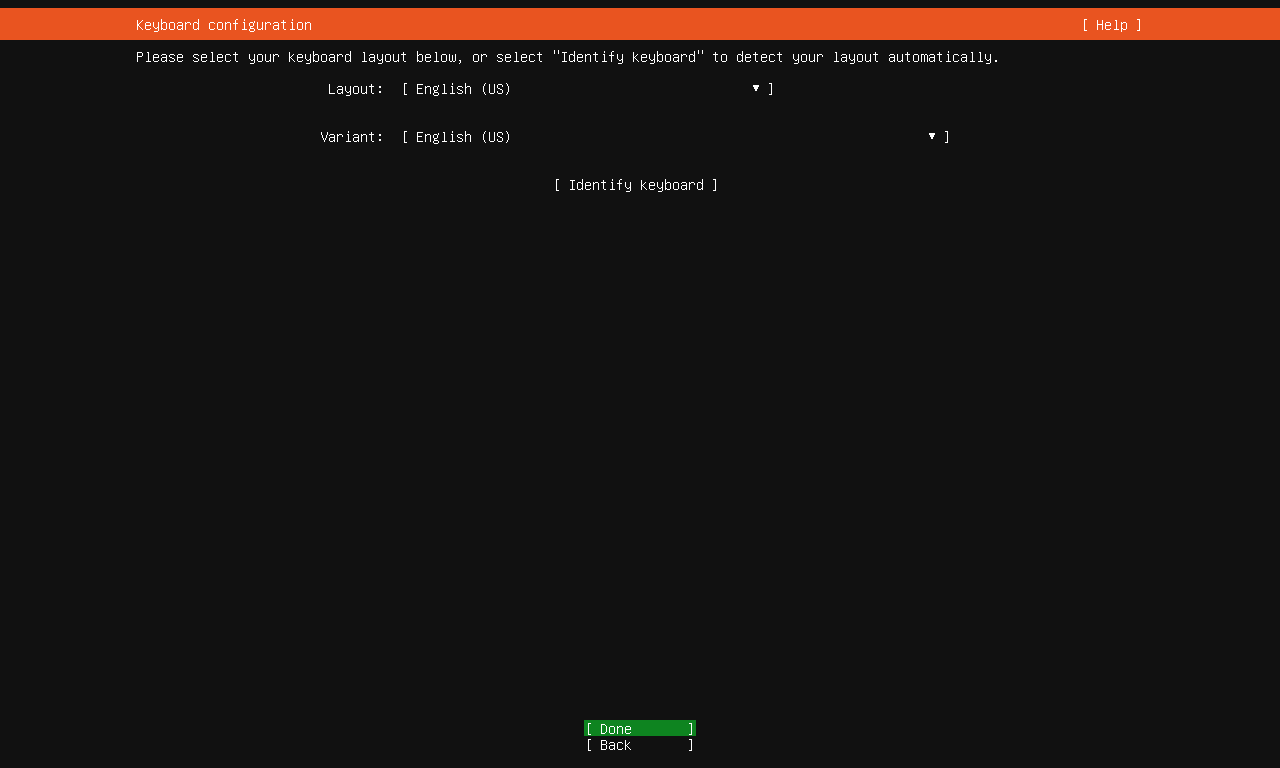
识别键盘布局¶
正常情况下,在国内购买的键盘大多为美式键盘(ANSI)布局,偶见 ISO 布局键盘,这里我们可以直接按 Tab 选择 Done 跳过。
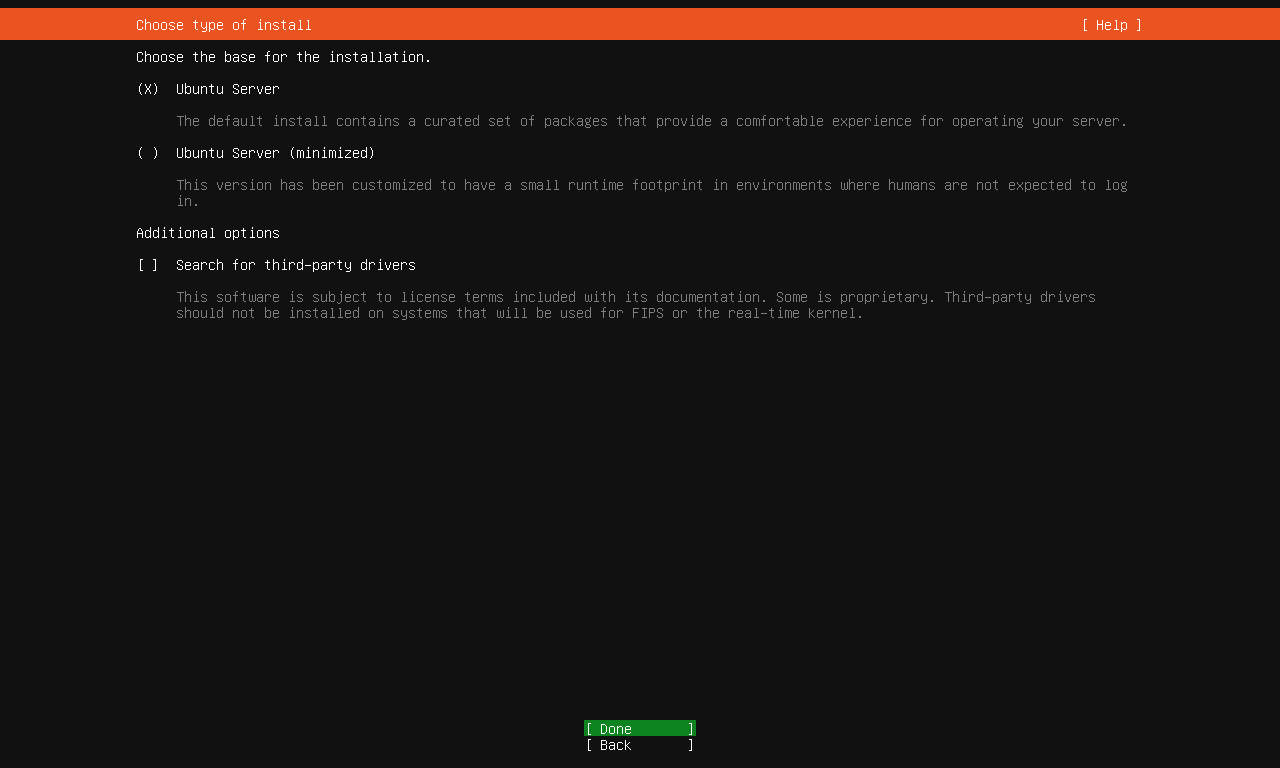
选择安装类型¶
在 Ubuntu 22.04,Canonical 新增了“最小版本”服务器安装,我们不需要最小版本,以免缺少一些常用工具,保持默认选择 Ubuntu Server,选择 Done 继续。
网络设置¶
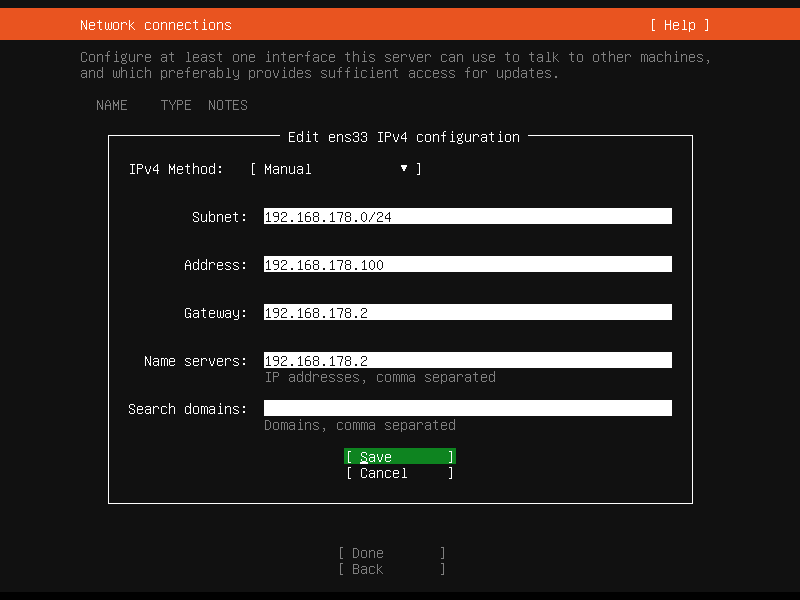
接下来迎接我们的就是网络设置页面。在 NAT 模式下,默认采用 DHCP 方式为虚拟机动态分配 IP 地址,我们需要让虚拟机主动“认领”属于自己的静态 IP 地址。
- 记下 DHCP 服务为你分配的 IP 地址,这次我们将使用
192.168.178.123 - 在你的设备上,这个第三段可能不是
178,你需要在接下来出现178的时候将其更换成符合你的情况的数字 - 使用方向键选中
[ens33 eth - ▶︎],回车进入子菜单 - 选择
Edit IPv4 - 选择
Automatic (DHCP) - 选择
Manual - 填写所有字段,保持 IPv4 地址前三段不变:
- Subnet:
192.168.178.0/24 - Address:
192.168.178.100 - Gateway:
192.168.178.2 - Name servers:
192.168.178.2 - Search domains 留空
- Subnet:
- 选择
Save保存设置 - 等待屏幕底部
Applying changes动画消失后,选择Done完成网络配置
情况可能不一样
不同的设备上,VMware 自动选择的子网可能不一样。比如新的虚拟机可能拿到 192.168.114.51 这个地址,在此情况下,通常将上文中所有 178 都替换为 114 即可。接下来的步骤中,请记住这个小提醒,而不是盲目地复制形如 192.168.178.xxx 的 IP 地址。
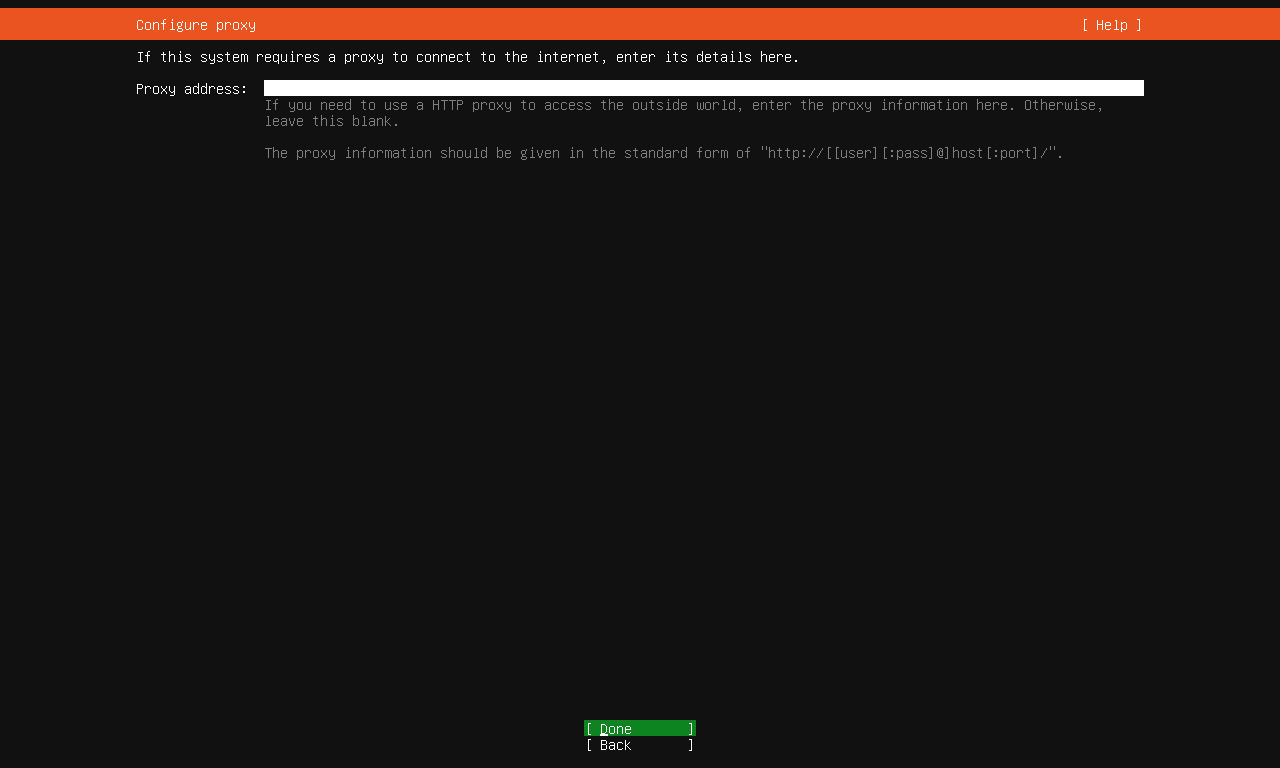
代理服务器配置¶
仔细看!
不要把镜像地址填写到代理服务器配置中,否则会导致后续 apt 无法联网。
此时我们来到了代理服务器配置,这在使用企业网络时通常有用,我们不需要,直接选择 Done 继续。
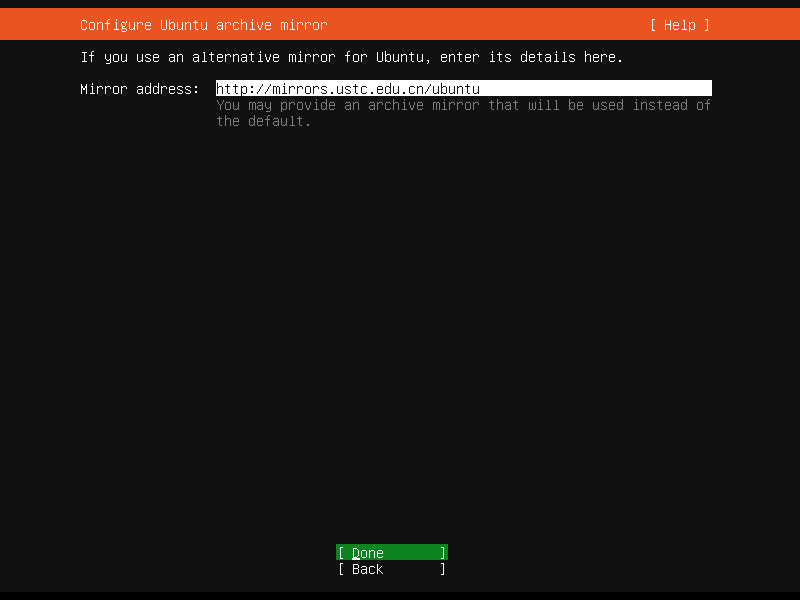
镜像源配置¶
为什么不用 HTTPS?
是的,HTTPS 的确更安全,但绝大多数主流 Linux 发行版的包管理器都有一套自己的校验机制(通常是基于 GnuPG),保证软件包不被篡改。即使是 HTTP 连接也可以放心使用。HTTPS 连接有可能会因为 ca-certificates 包过老等原因失败,但 HTTP 不会。
接下来是镜像服务器配置,我们使用中国科学技术大学的开源软件镜像源,填入以下地址:
硬盘格式化¶
接下来进入硬盘格式化页面(放心,格式化的是虚拟机的硬盘,不是主机硬盘),使用方向键移动到 [ ] Set up this disk as an LVM group 上,按回车键取消勾选,随后继续至下一页。
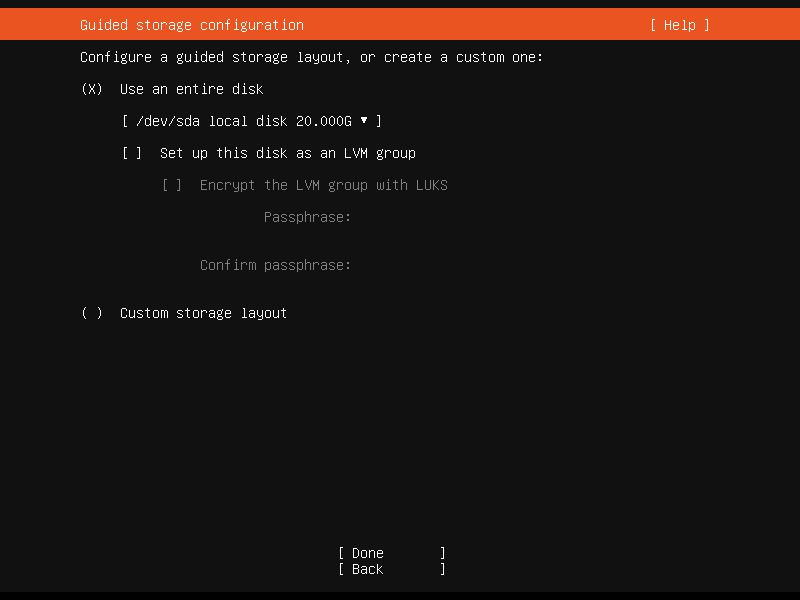
在这一页我们可以检查格式化配置,默认配置即可,回车继续。
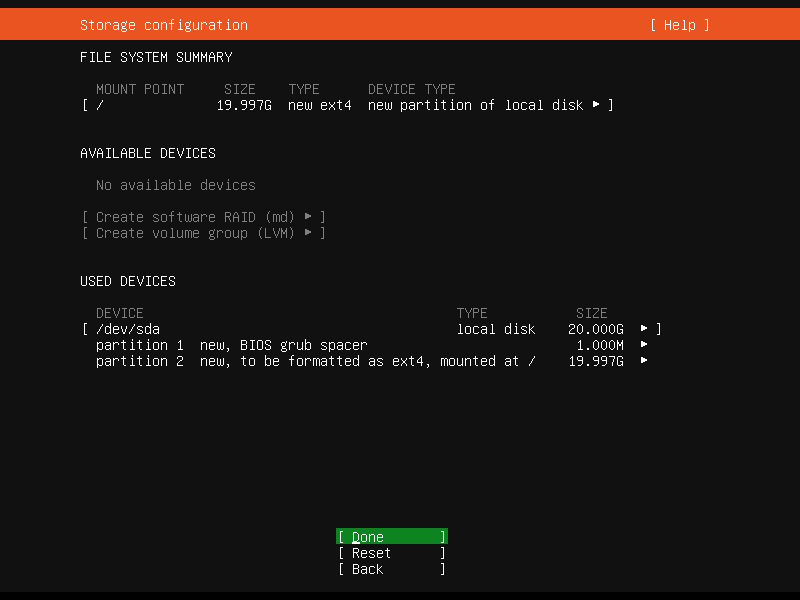
系统会提示我们是否确定(因为存在先有数据在格式化过程中丢失的风险),直接选择 Continue 即可。
用户配置¶
在接下来的页面,配置默认管理员用户的信息,我们使用 super 作为管理员用户的用户名。当然,你也可以自定义一个属于你自己的用户。
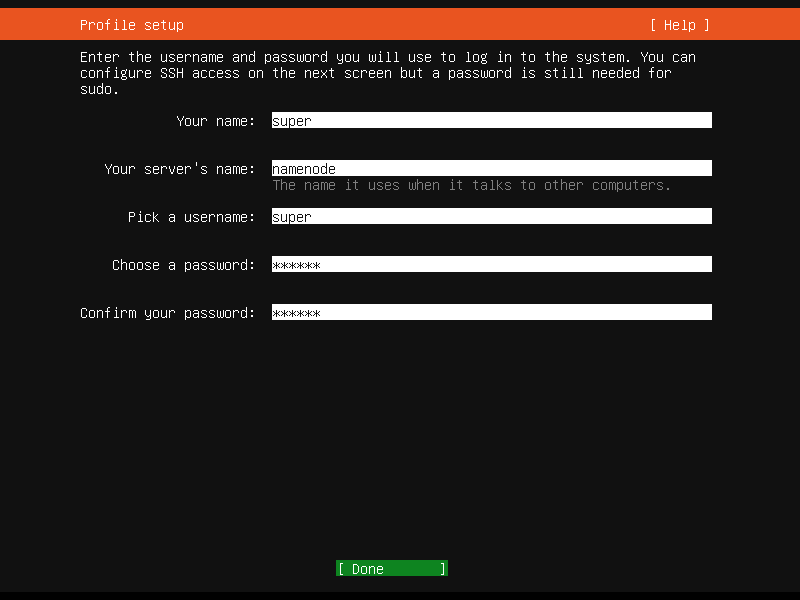
系统安装前的小插曲¶
恭喜!现在我们达到了正式的系统安装步骤,可以休——等等,你还要配置一些别的东西。
我们不需要 Ubuntu Pro 的功能,暂且跳过,选择 Skip for now.
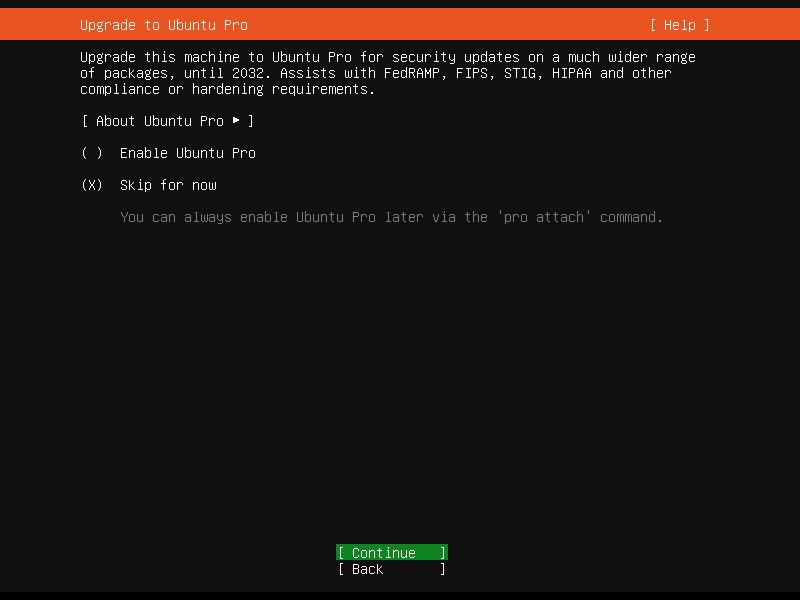
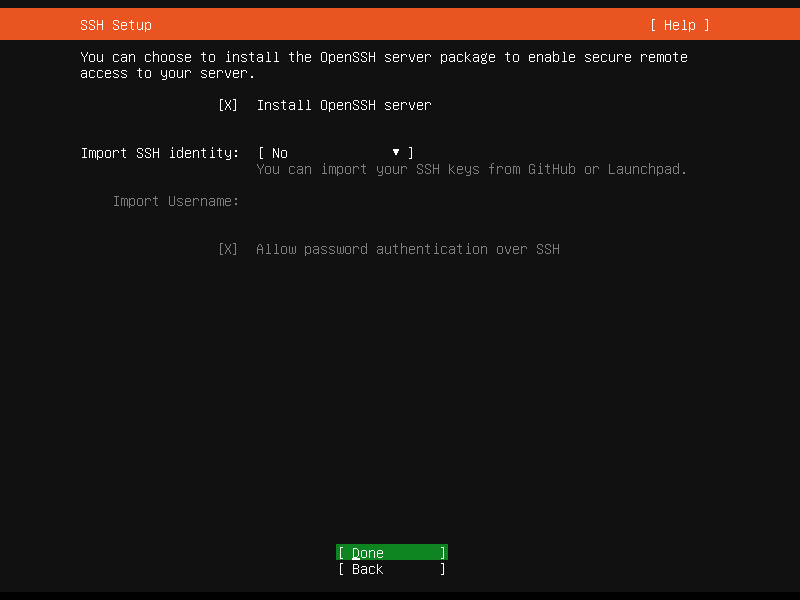
在新的页面,选择 [ ] Install OpenSSH server,按回车键勾选,然后选择 Done.
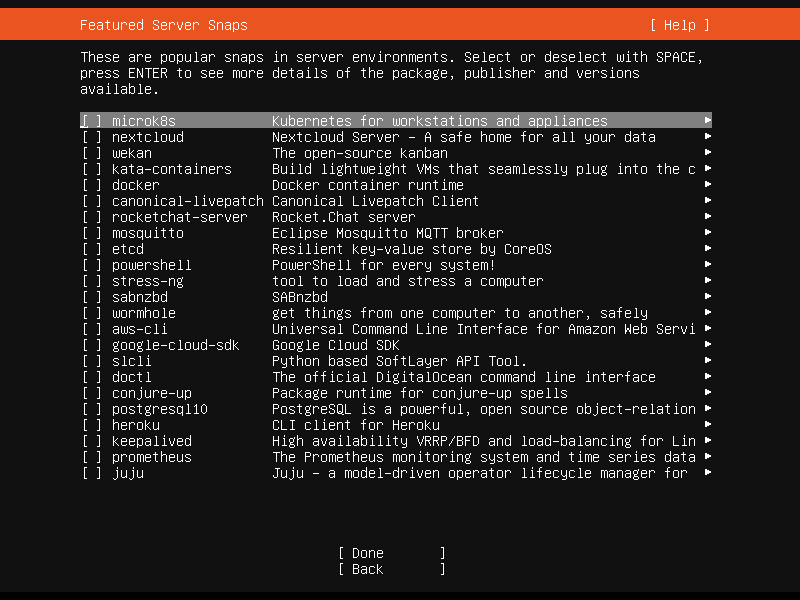
Ubuntu Server 是一个热门的服务器操作系统,下一个页面会询问你是否需要一些主流环境,只可惜我们不需要。按下 Tab 键,选择 Done.
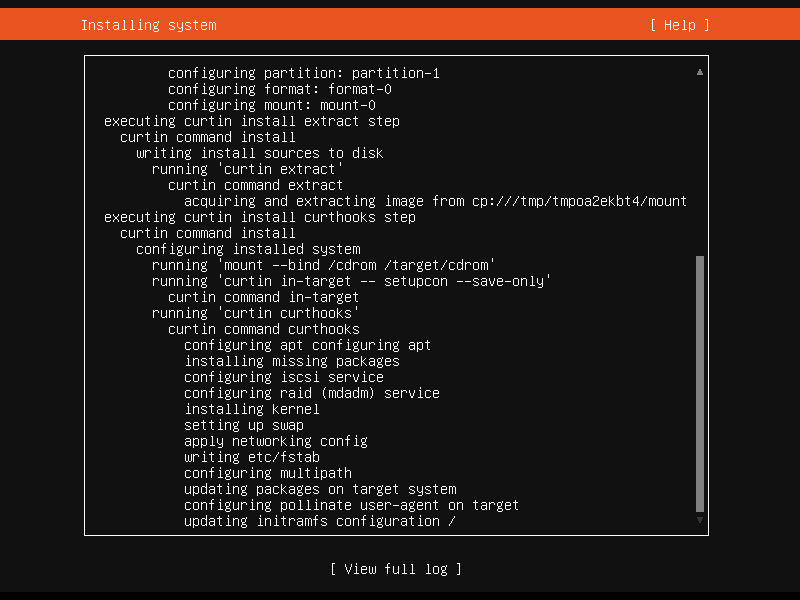
系统安装¶
现在,我们来到了系统安装界面,等待系统安装完成。
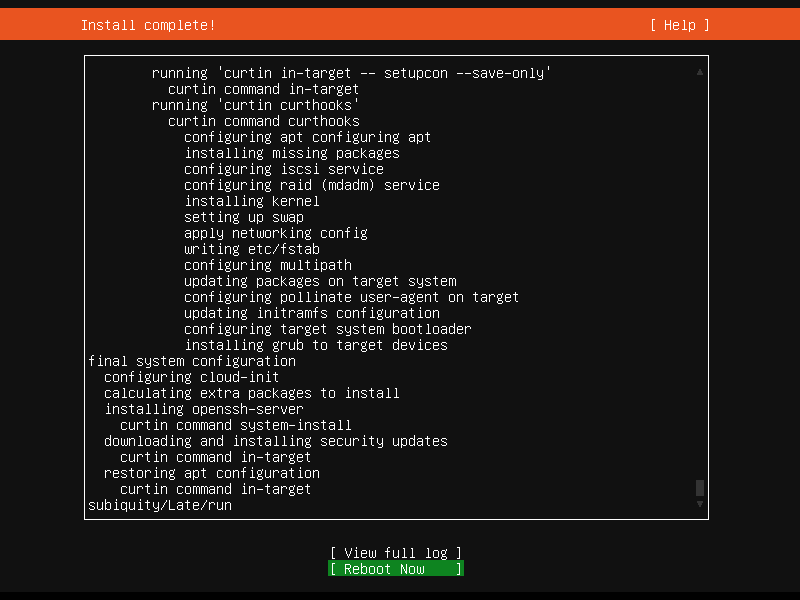
完成!¶
可能不是那么的显眼,但安装过程通常较快,待底部菜单出现 [ Reboot Now ] 时,即可将其选中,确定重启,完成安装。
卡住了?¶
如果你遇到满屏幕的 Failed unmounting /cdrom,没关系,检查虚拟机软件界面(VMware Workstation Player 的右下角,VMware Fusion Player 的标题栏)的光驱连接状态。
如果光驱尚未弹出,点击后,选择断开连接。如果光驱已经弹出,在虚拟机中按下回车即可。
初来咋到!¶
咋回事?
TTY 的显示原理,可能出现 getty 启动后输出的提示信息被日志覆盖掉的情况,而此时 getty 已经在运行,等待用户登录。你也可以长按回车键,用刷屏的方式清空日志。
在重启后,如果长时间未出现新的日志项目,这个时候 getty 可能已经启动,可以登录了。按下回车键(可以多按几次),应该就会出现 namenode login: 的提示。如果没有,再重启一次。

首次登录¶
输入之前设置的管理员用户名和密码,登录到系统。
Hadoop 安装¶
终于!可以进入真正的重头戏了:Hadoop 的安装和配置。在此之后,我们需要克隆出两台相同的机器作为其他节点。
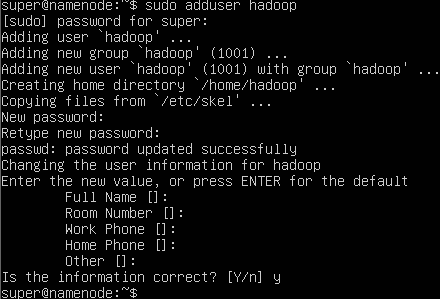
创建 Hadoop 用户¶
使用以下命令创建新用户:
为什么不用 useradd?
adduser 是 Debian 系 Linux 发行版的独有命令,而 useradd 可用于所有 Linux 发行版中,层级更低,不建议使用。如果你使用了其它发行版,没关系!可以使用以下命令创建用户:
随后可以使用
来修改 hadoop 用户的密码。
如果被提示到 super 或你创建的管理员用户的密码,输入并按下回车确认。
随后为 hadoop 用户设置密码,接下来提示设置全名等信息可以不填,直接回车跳过。最后被问及信息是否正确,直接按回车确定。
看清用户名!
在被问及输入密码时,一定要仔细确认“这是要输入谁的密码”,在 sudo 时需要输入的是执行 sudo 命令的用户的密码,并且会在提示中显示用户名。
虽然说对于母语为中文的我们来说,英语不是那么易读,但也不能完全不读。
安装 Hadoop¶
- 在虚拟机中,创建 Hadoop 安装目录:
- 在主机上:
- 找到我们刚刚下载的 Hadoop 文件(
hadoop-3.3.6.tar.gz)。 - 打开:
- 终端
- 命令提示符(Windows 10)
- :simple-windows11: Windows 终端(Windows 11)
- 使用
cd进入到所在文件夹,比如:-
cd ~/Downloads -
cd %USERPROFILE%\Downloads
-
- 使用该命令传输文件到虚拟机:
- 找到我们刚刚下载的 Hadoop 文件(
注意用户名!
如果你的虚拟机管理员用户名不是 super,你需要在这里将它替换为你的管理员用户名。
找不到 scp 或者 ssh 命令?
如果出现找不到命令的情况,请参考常见问题 scp 命令未找到。
我们来偷懒:在虚拟机里,输入 exit 退出 hadoop 用户登录,再运行一次 exit 退出 super 用户登录,然后最小化/隐藏虚拟机软件界面。
在 getty 下,主机与虚拟机的剪贴板并不共享,也没有剪贴功能。这种情况下是无法使用复制粘贴功能的。但可以曲线救国:在主机的终端/命令提示符下,使用 ssh 连接到虚拟机:
- 使用
super用户登录 - 连接到
192.168.178.100
如果提示,输入 yes 信任虚拟机,输入密码登录,随后即可将内容粘贴至虚拟机中。
我们现在在虚拟机中,进行以下操作:
- 将 Hadoop 压缩包移动至目的地
- 前往 Hadoop 安装目录:
- 解压缩:
- 调整位置:
仔细阅读!
以上命令的末尾有一个点(.),在输入的时候务必不要遗漏。
- 移除目录:
- 移除压缩包:
- 修正权限:
仔细阅读!
以上命令的末尾有一个点(.),在输入的时候务必不要遗漏。
- 修改
profile: - 添加以下内容:
- 按下 Ctrl+X,确认保存(按 Y),确认文件名(回车 Enter)
- 应用变更:
source /etc/profile
不是所有事情都是需要 sudo 的
Linux 有一个常见误区:无法完成想做的事情?加上 sudo 试试。在真正需要管理系统的权限时,应当使用 sudo 来提升权限,其他时候都不应该。反之,应当仔细检查其它可能的出错原因。sudo 的误用往往是一时解决了问题,但却会在后期带来更多的隐形的问题。同时任意 sudo 也有可能破坏系统安全,为系统带来安全隐患。在这一步,我们执行的基本都是系统管理命令,必须使用 sudo 才能正常完成。
安装 Java¶
为什么还在用 Java 8?
连 Minecraft 1.18 都需要 Java 19 或更高版本才能启动了。但至于 Hadoop,这是一个需要去问 Apache 的问题。Hadoop 目前仅有 Java 8 的完整支持,Java 11(2018 年发布)仍然处于“实验性”阶段。所以很抱歉,我们只能用 Java 8 了。
- 安装 OpenJDK 包4:
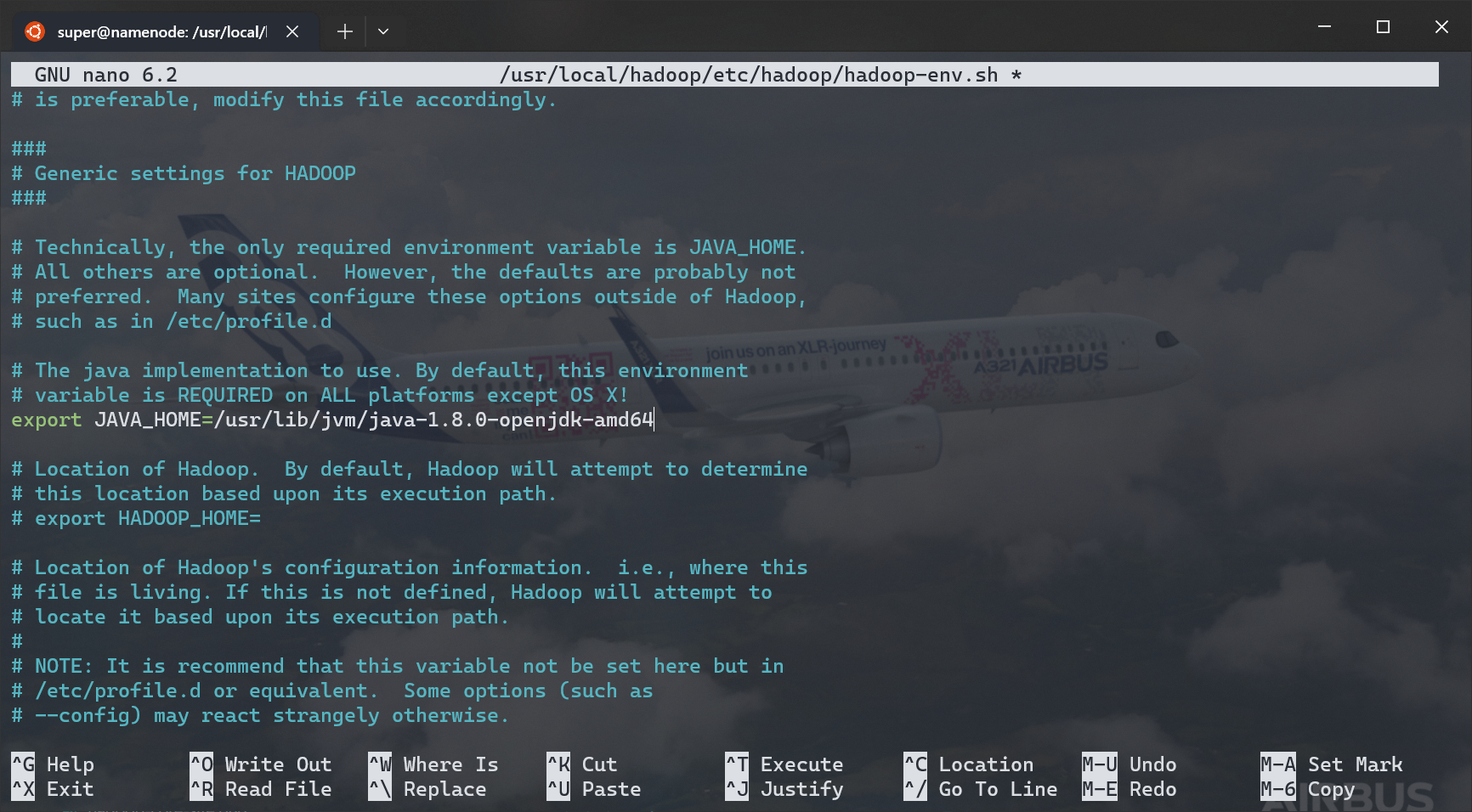
- 修改 Hadoop 运行环境配置:
- 按 Ctrl+W,输入
JAVA_HOME寻找JAVA_HOME环境变量配置位置 - 找到如下图位置,去除
#来取消注释,填入:
- 按 Ctrl+X 保存
切换到 Hadoop 用户¶
使用以下命令切换到 hadoop 用户:
输入 hadoop 用户的密码,完成登录。
- 如果遇到
su: Authentication failure,则说明密码有误,需要重新尝试 - 如果看到
hadoop@namenode:~$显示,则说明登录成功
此时可以执行 hadoop version 命令,如果显示 Hadoop 版本信息,则说明没有问题,可以继续。
Hadoop 配置¶
接下来我们执行 Hadoop 的配置。使用:
命令,进入配置文件夹。
core-site.xml¶
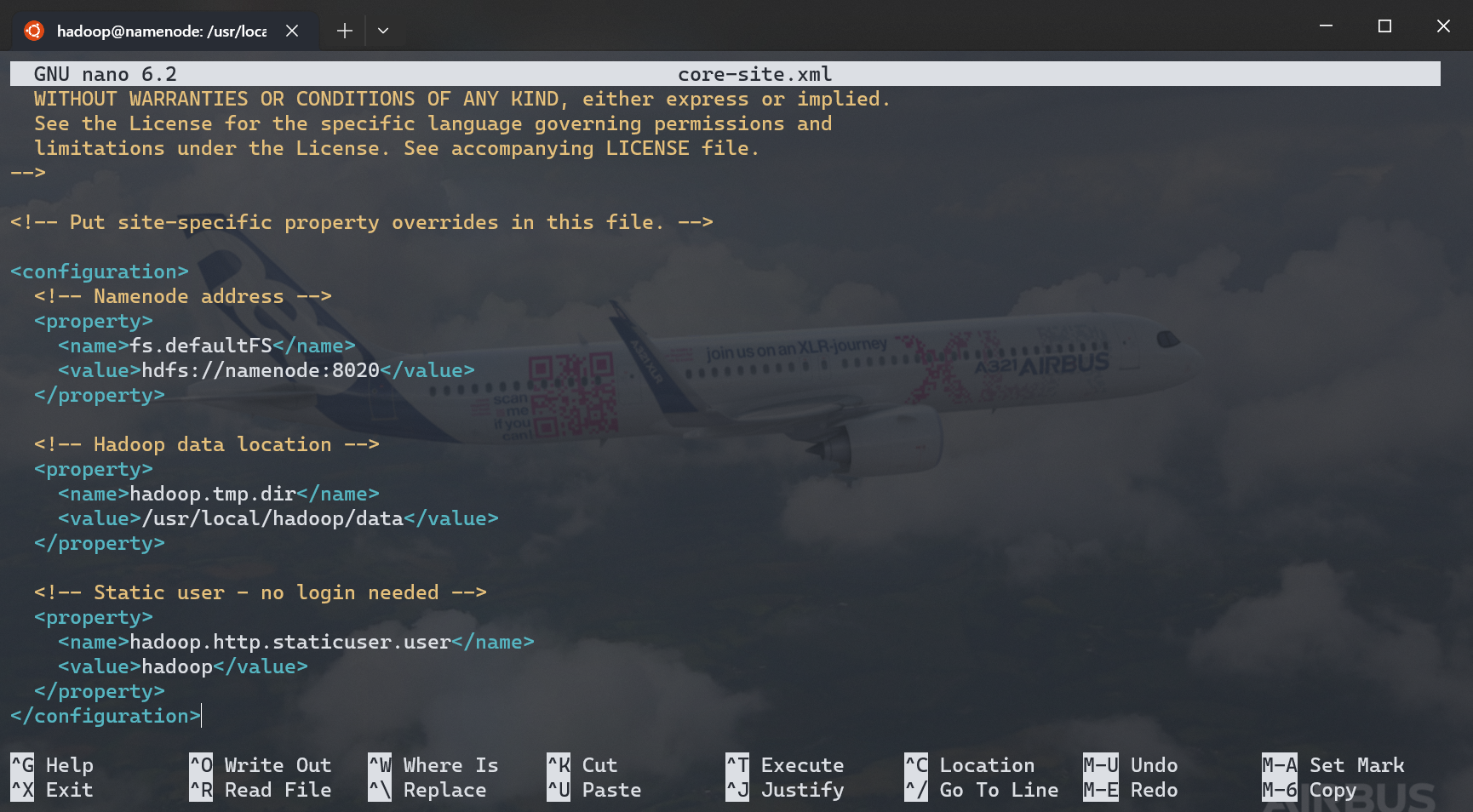
执行 nano core-site.xml,在 <configuration> 块内填写以下信息(注释可以不添加):
<configuration>
<!-- Namenode address -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://namenode:8020</value>
</property>
<!-- Hadoop data location -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/data</value>
</property>
<!-- Static user - no login needed -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>hadoop</value>
</property>
</configuration>
hdfs-site.xml¶
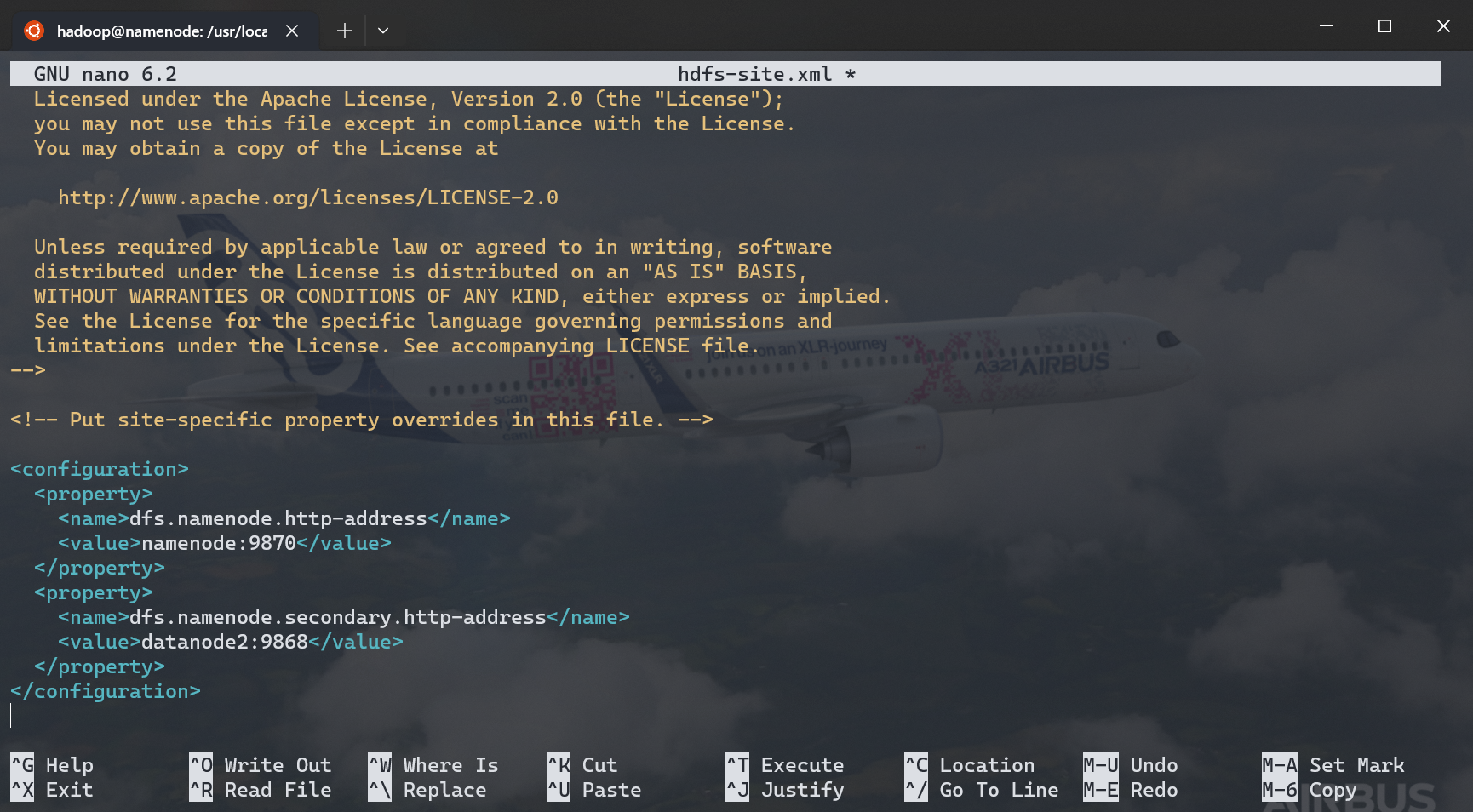
类似地,编辑 hdfs-site.xml,在 <configuration> 块内填写以下信息:
<configuration>
<property><!-- (1)! -->
<name>dfs.namenode.http-address</name>
<value>namenode:9870</value>
</property>
<property><!-- (2)! -->
<name>dfs.namenode.secondary.http-address</name>
<value>datanode2:9868</value>
</property>
</configuration>
- 主 Namenode 地址
- 第二 Namenode 地址
yarn-site.xml¶
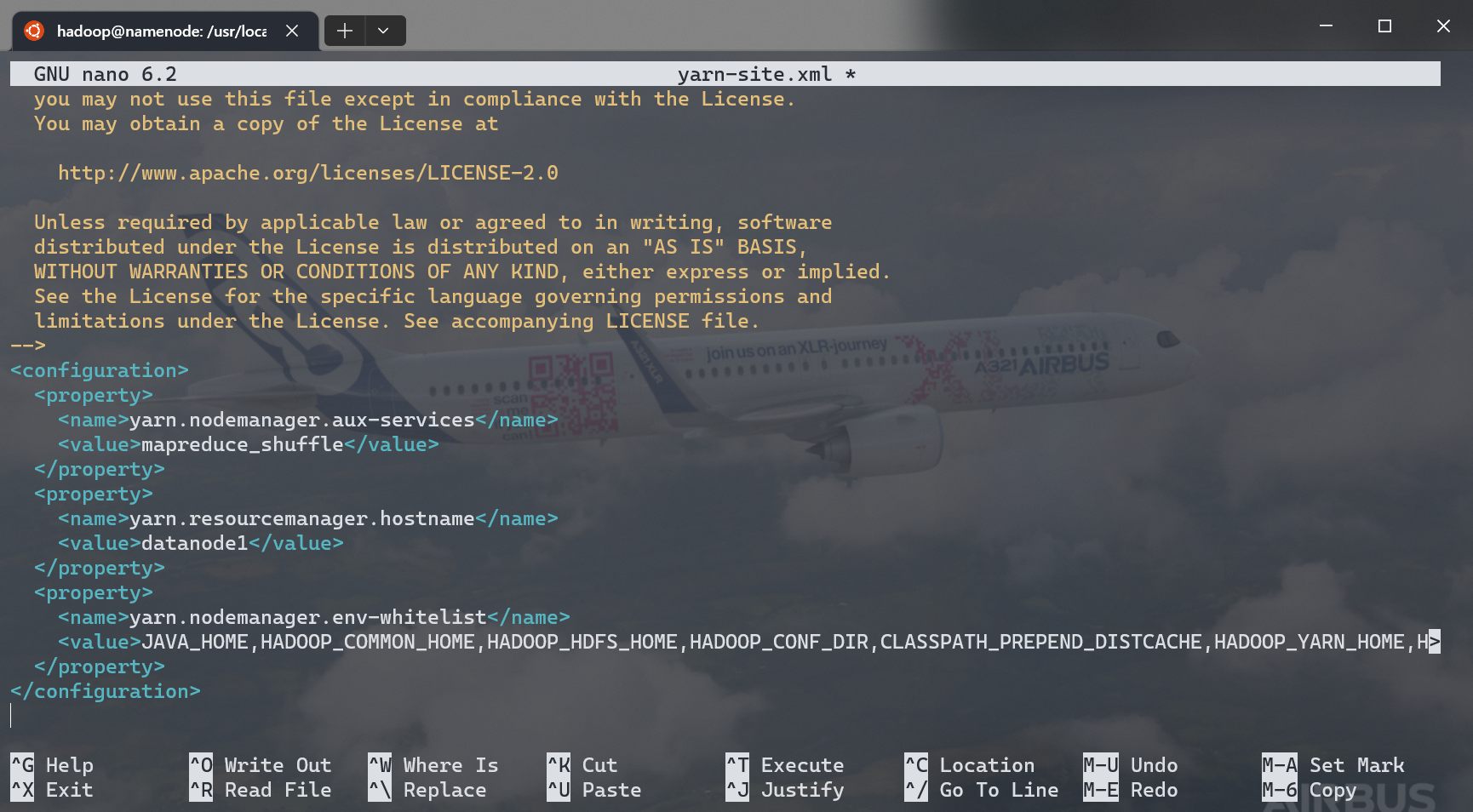
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager<!-- (1)! -->.hostname</name><!-- (2)! -->
<value>datanode1</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
- 如果你正通过 Web VPN 访问此文档,复制时,请务必查看下方提示框内容
- 指定 YARN 在
datanode1运行
如果你正在使用 Web VPN 访问此文档
学校使用的深信服 Web VPN 存在一个已知 bug,可能会将上方代码中的 yarn.resourcemanager.hostname 替换为 proxyLoc(yarn.resourcemanager).hostname,请务必参照下方截图确认你的配置无误。
嗯,是的,其实我在编写的时候也被顺手坑了一把。
如果在启动 YARN 后发现只有 1 个活跃节点,大概率就是在这里被坑了。
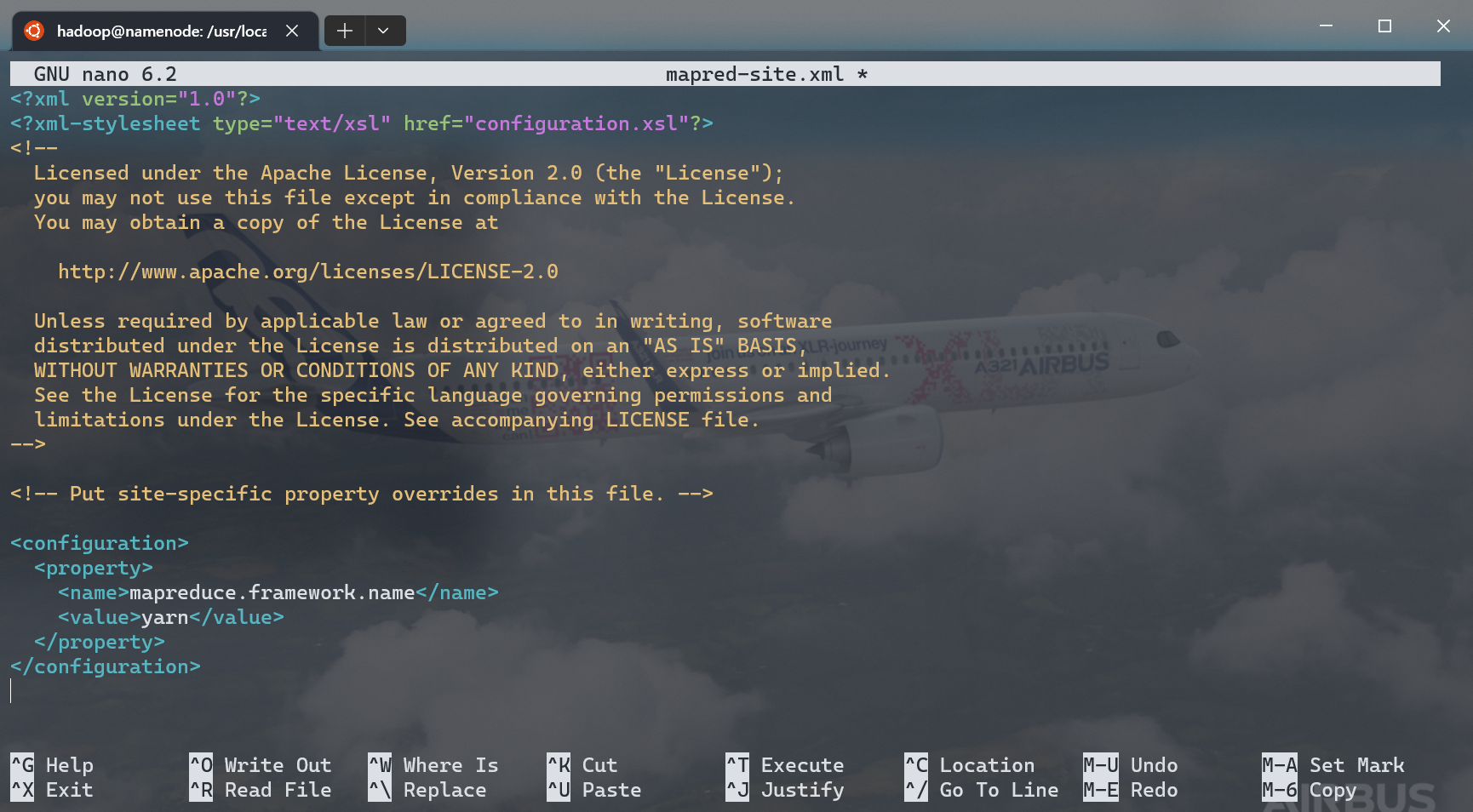
mapred-site.xml¶
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
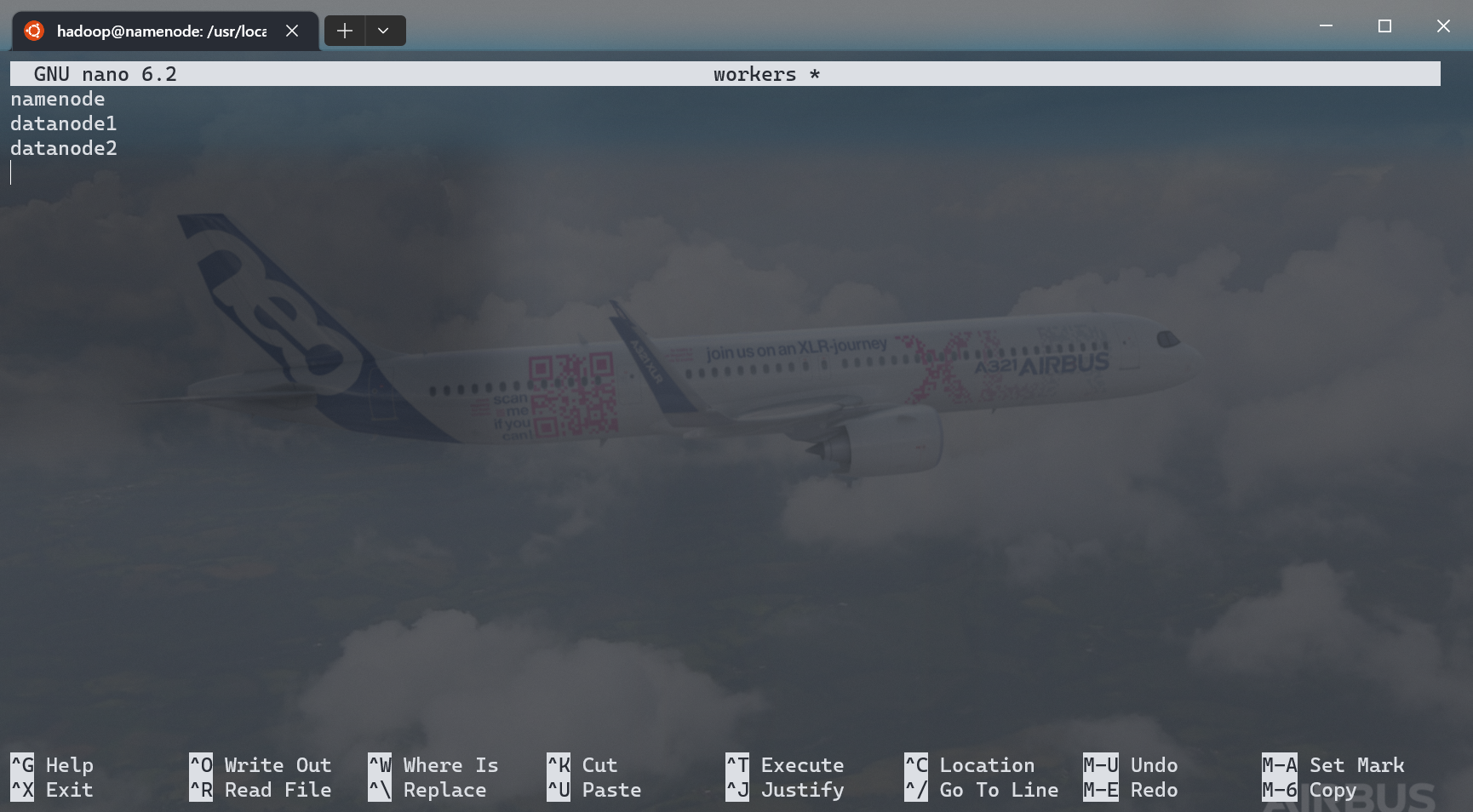
workers¶
- 修改
workers文件: - 移除自带的
localhost - 填入以下内容:
- 保存
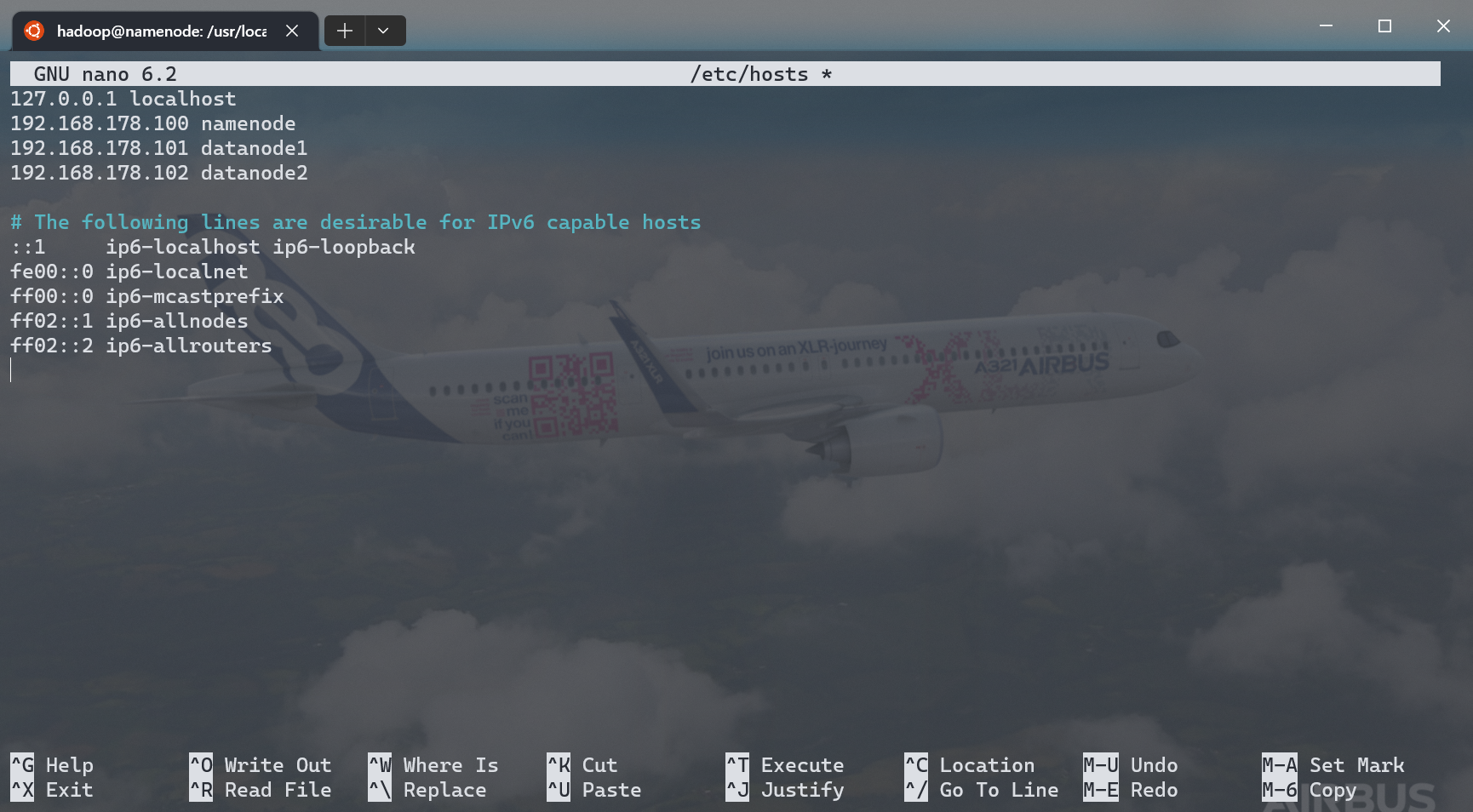
配置网络¶
- 退出
hadoop用户:exit - 此时应当回退到了
super用户,如果没有,重新登录 - 修改
hosts: - 修改
127.0.0.1 namenode为192.168.178.100 namenode - 添加以下两行:
- 保存退出
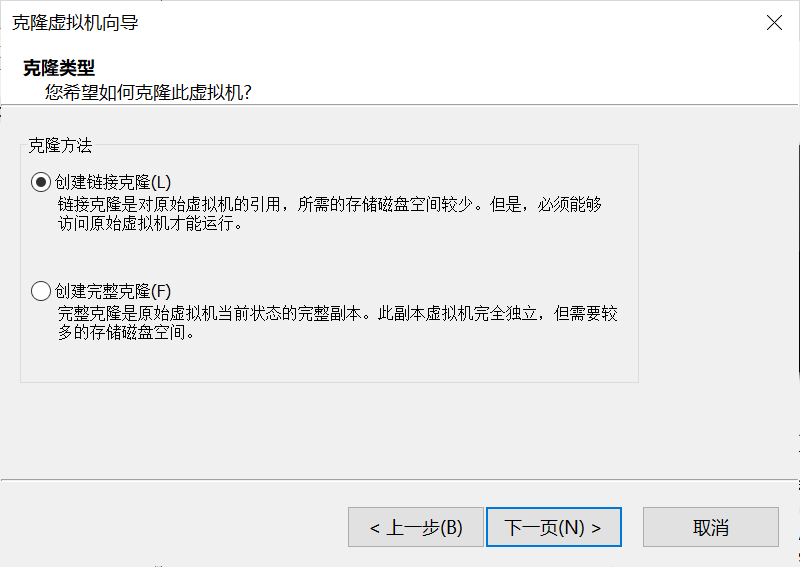
克隆虚拟机¶
我们需要三台虚拟机作为真分布式 Hadoop 集群中的三台机器。我们以配置好的 namenode 为蓝本,创建另外两台机器。
克隆文件¶
- 关机:
- 在虚拟机软件中,右键 namenode,连续使用两次“创建链接克隆”5,保存为 datanode1 和 datanode2
如果你没有看到“克隆虚拟机”选项
这个功能只在 VMware Workstation Pro 中提供,VMware Workstation Player 无此功能。你可以切换到 VMware Workstation Pro 打开 namenode
虚拟机再执行克隆操作(二者格式互相兼容),也可以直接复制一份 namenode 虚拟机所在的文件夹,再双击打开新的文件夹内的 .vmx 文件。链接克隆的好处请参考附注5。
配置克隆机网络¶
- 开启 datanode1,如果提示是复制了还是移动了虚拟机,选择“我已复制该虚拟机”
- 登录到
super用户 - 修改主机名:
- 修改 IP 配置:
- 将
addresses:下的192.168.178.100/24替换为192.168.178.101/24 - 保存退出
- 重启虚拟机:
- 登录到
super用户 - 验证 IP 地址:
ip addr - 出现
inet 192.168.178.101/24即表示设置正确
- 登录到
- 开启 datanode2,如果提示是复制了还是移动了虚拟机,选择“我已复制该虚拟机”
- 登录到
super用户 - 修改主机名:
- 修改 IP 配置:
- 将
addresses:下的192.168.178.100/24替换为192.168.178.102/24 - 保存退出
- 重启虚拟机:
- 登录到
super用户 - 验证 IP 地址:
- 出现
inet 192.168.178.102/24即表示设置正确
- 登录到
在三台机器上配置公钥登录¶
- 在三台同时运行的虚拟机上,各自:
- 切换到
hadoop用户: - 生成公钥对:
- 按三次回车!(即全部使用默认配置)
- 切换到
- 保证上述三个步骤已在三台机上全部执行完毕后,逐一完成公钥复制:
- 在每台机器上运行这三个命令:
- 根据提示,如果询问是否信任主机,输入
yes - 如果询问
hadoop用户密码,输入对应的密码 - 在三台机器中的每一台机器上,均需执行上述所有三个命令
格式化 HDFS¶
在初次运行前,我们需要格式化 HDFS.
- 在 namenode 机器上,使用
hadoop用户身份:- 格式化 HDFS:
不要重复格式化!
请勿多次格式化 HDFS,否则会导致 cluster ID 不匹配,继而 datanode 无法启动。
启动集群¶
- 在 namenode 机器上,使用
hadoop用户身份:- 启动集群:
- 在 datanode1 机器上,使用
hadoop用户身份:- 启动 YARN:
如果需要停止集群,只需要在 namenode 执行 stop-dfs.sh,在 datanode1 执行 stop-yarn.sh 即可。
谨慎使用 start-all.sh
由于 YARN 被配置在 datanode1 运行,只能在 datanode1 机器上执行 start-yarn.sh 来启动 YARN,否则会导致启动失败。即使 HDFS 可以访问,YARN 也会工作异常,无法为后续如实验五提供支持。
结束了?¶
恭喜你!Hadoop 的搭建工作就到此为止了。
可以在浏览器输入以下地址,访问对应的控制面板:
| 网页 | 地址 |
|---|---|
| HDFS 控制面板 | http://192.168.178.100:9870 |
| YARN 控制面板 | http://192.168.178.101:8088 |
可以输入 jps6 命令,查看正在运行的模块信息。
成功的标志¶
如果实验顺利完成,一共有以下几个成功标志:
启动和停止过程¶
启动过程应该输出类似:
hadoop@namenode: ~ $ start-dfs.sh
Starting namenodes on [namenode]
Starting datanodes
Starting secondary namenodes [datanode2]
hadoop@datanode1: ~ $ start-yarn.sh
Starting resourcemanager
Starting nodemanagers
停止过程应该输出类似:
hadoop@datanode1: ~ $ stop-yarn.sh
Stopping nodemanagers
Stopping resourcemanager
hadoop@namenode: ~ $ stop-dfs.sh
Stopping namenodes on [namenode]
Stopping datanodes
Stopping secondary namenodes [datanode2]
启动或停止过程不应该出现任何 WARNING 或报错信息。不应该出现 XXX did not exit gracefully 信息。
首次启动?
首次启动可能会出现这类警告信息:
datanode1: Warning: Permanently added 'datanode1' (ED25519) to the list of known hosts.
datanode2: Warning: Permanently added 'datanode2' (ED25519) to the list of known hosts.
这是首次 SSH 连接到其他服务器时的正常现象,不用担心。下次启动时应该就不会出现了。
如果出现这类警告信息:
datanode1: WARNING: /usr/local/hadoop/logs does not exist. Creating.
datanode2: WARNING: /usr/local/hadoop/logs does not exist. Creating.
这是 datanode1 和 datanode2 首次运行 Hadoop 时正常产生的现象,因为没有日志目录,也不必担心。
三台服务器运行的后台任务¶
在三台服务器上以 hadoop 用户身份运行 jps6,应该得到以下输出(不分顺序):
namenode:datanode1:datanode2:
Hadoop 集群节点¶
打开 Hadoop 控制面板,在顶部导航栏中选择 Datanodes,你应该看到类似这样的界面:
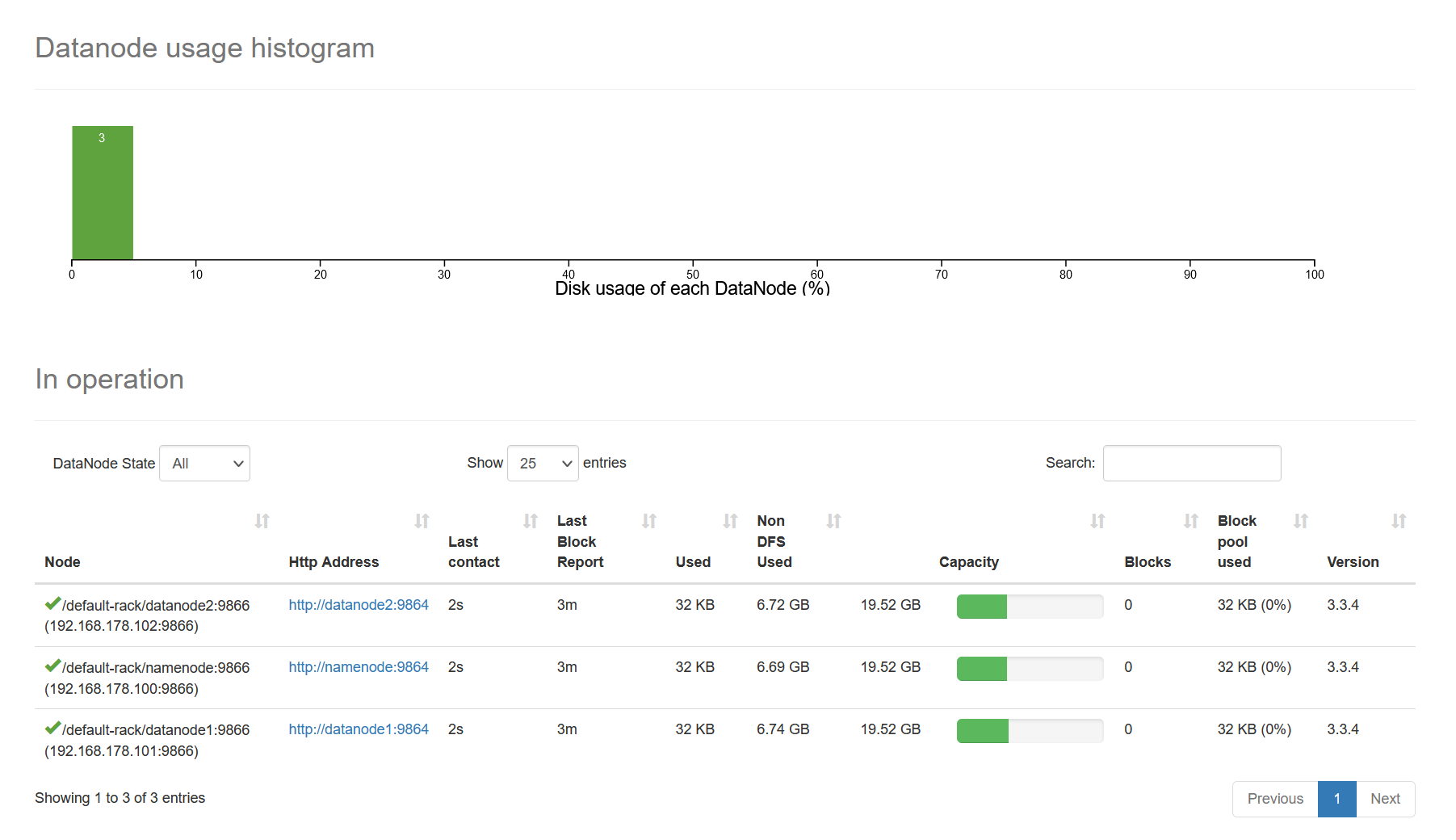
如果有三个数据节点,那么你的 Hadoop 集群就安装并全部启动成功了。
YARN 节点¶
打开 YARN 控制面板,你应该看到类似这样的界面:
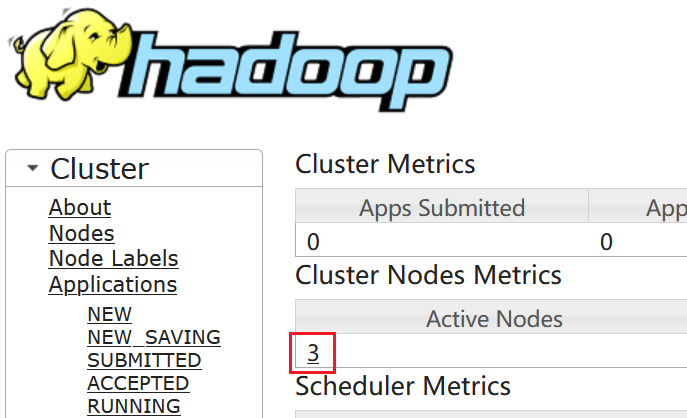
如果红框位置有三个数据节点,那么你的 YARN 的配置就是正确的并启动成功了。
自动验证¶
我们开发了一个自动验证工具(目前仅可用于 Windows),你可以使用它验证自己的实验结果。
在此处下载。
※ 由于是独立开发应用,Microsoft Defender 反病毒应用程序可能误触发自动提交样本。
那以后呢?¶
未来,如果想要启停 Hadoop 环境,步骤如下:
- 三台机器全部开机,随后:
namenode:- 登录到
hadoop用户 - 运行
start-dfs.sh - 结束,可输入
exit退出登录
- 登录到
datanode1:- 登录到
hadoop用户 - 运行
start-yarn.sh - 结束,可输入
exit退出登录
- 登录到
datanode2: 什么都不用做
如果需要停止 Hadoop 环境,将 start 替换为 stop 即可。
我没法关机?
Hadoop 为低权限用户,可能没有关机权限,也没有 sudo 权限。此时可以退出登录,重新登录到 super 用户再执行 poweroff 命令。
FAQ / 常见问题¶
以下是对一些实验中较为常见的问题的解答。
其它系统配置¶
Q
我可以使用其他的 Linux 系统作为虚拟机系统吗?我可以使用 Ubuntu 22.04 桌面版或者 20.04, 18.04 进行实验吗?我可以用我最喜欢的 Arch Linux / Gentoo / nixOS 吗?
A
当然可以7。但需要注意的是系统版本的不同可能导致一些实验细节上的不一致,难免会出现一些意料之外的问题。
hadoop-env.sh 文件未找到¶
Q
在安装 Java 时,当我修改 /usr/local/hadoop/etc/hadoop/hadoop-env.sh 的时候,提示我文件未找到,是怎么回事?
A
你可能在安装 Hadoop 时,在 sudo mv hadoop-3.3.6/* . 这个命令遗漏了末尾的点(.)符号。这会导致错误的移动行为。类似地,如果在安装
Hadoop 过程中,chown 命令报错,提示 chown: missing operand after ...,你可能也是遗漏了这个 . 点。
apt 无法连接¶
Q
在安装 Java 时,apt 命令刷屏且不执行安装,怎么办?
A
你有可能错误地在代理设置页面填写了镜像地址,而没有真正地更改镜像地址。请使用以下命令删除代理配置:
随后使用:
检查 apt 联网是否正常。
scp 连接超时¶
Q
我在尝试使用 scp 复制 Hadoop 包时,提示:
ssh: connect to host 192.168.178.100 port 22: Connection timed out
怎么办?
A
此问题常见于 Windows,可能是以下几种情况:
- 你为虚拟机设置错了子网,比如你的虚拟机所在的子网并不是
192.168.178.0/24但你却设置成了这样 - 你的虚拟网卡缺失
你可以尝试:
- 打开任务管理器
- 切换到“性能”标签页
- 检查是否有“以太网”图表,下方适配器名称为
VMware Network Adapter VMnet8(或与你的虚拟化软件对应的名称)

- 如果没有,或者只看到了“WLAN”与/或“以太网”,说明你的问题是上述第二种情况,你需要重新安装你的虚拟化软件
- 点击该图表,查看“IPv4 地址”一栏,确定你所在的子网,如
192.168.110.1,对应的就是192.168.110.0/24 - 在虚拟机运行以下命令:
- 替换所有此前的“第三段数字”为你在任务管理器里看到的新的“第三段数字”(如本例子中的
178应为110) - 保存,运行
sudo reboot重新启动虚拟机
scp 无法确认连接¶
Q
我在 Windows 上复制 Hadoop 包时,我被提示:
The authenticity of host '192.168.178.100 (192.168.178.100)' can't be established.
ECDSA key fingerprint is SHA256:XXXXXXXXX.
Are you sure you want to continue connecting (yes/no/[fingerprint])?
但是我输入 yes 时无反应,怎么办?
A
你的中文输入法(尤其是搜狗拼音)正在妨碍控制台输入,切换至英文模式,或切换输入法,再输入 yes 回车即可。
自动信任
你也可以使用以下命令自动信任虚拟机(注意修改成你虚拟机的 IP):
scp 命令未找到¶
Q
我在 Windows 上复制 Hadoop 包时,我被提示:
'scp' 不是内部或外部命令,也不是可运行的程序或批处理文件。
怎么办?
A
这通常意味着你的电脑并没有 scp 命令。你需要 Windows 10 April 2018 Update (1803, build 17134) 或更高版本,并且已经安装可选功能“OpenSSH 客户端”。你可以尝试以下步骤重新启用 scp 命令:
不想用命令行?
你也可以下载图形化应用 WinSCP 来替代 scp 命令进行文件传输。
- 前往“设置” 应用 应用和功能 可选功能
- 选择“添加功能”
- 勾选“OpenSSH 客户端”
- 选择“安装”
安装过程需要网络连接。等待安装完成后,你应该就可以使用 scp 和 ssh 命令了。如果你没有看到这个可选功能,你可能正在使用偏旧的 Windows 10,可以运行 winver 命令确认“操作系统内部版本”(需 >17134)。
ssh 或 scp 提示远程指纹更改¶
Q
我因为问题重做了实验(重新安装了 OS), 但在 SSH 或 SCP 连接时,我遇到这样的警告,怎么办?
WARNING: REMOTE HOST IDENTIFICATION HAS CHANGED!
A
这是正常现象,是 OpenSSH 的安全功能之一。重新安装后会导致公钥发生变化而不匹配导致无法连接。你可以使用以下命令移除对此前公钥的记忆:
启动集群时提示权限拒绝¶
Q
我在启动 Hadoop 集群时,得到这种错误,怎么办?
datanode1: hadoop@datanode1: Permission denied (publickey,password).
datanode2: hadoop@datanode2: Permission denied (publickey,password).
A
你的公钥登录配置错误。请检查“克隆虚拟机”章节。
启动集群后看不到 datanode¶
Q
我的集群启动正常,但启动后在 Datanodes 页面看不到任何 datanode,如何解决?
A
你可能多次格式化了 HDFS,导致 cluster ID 不匹配。如要修复,请先确保集群未在运行,再在三台机器上删除 /usr/local/hadoop/data 目录,或者复制以下命令在任意节点执行:
command="rm -rf /usr/local/hadoop/data"
ssh namenode "$command"
ssh datanode1 "$command"
ssh datanode2 "$command"
并在 Namenode 上格式化一次 HDFS.
完成后,启动集群。
Changelog / 更新日志¶
以下为一些本手册的主要变化,可能不包括所有变更。
- 2023/03/21
- 根据实验结果,添加了两个常见问题解答
ssh或scp提示远程指纹更改- 启动集群后看不到
datanode
- 根据实验结果,添加了两个常见问题解答
- 2023/03/11
- 新增首次启动时日志目录不存在的警告信息提示
- 为
scp命令用户名添加了提示
- 2023/03/09
- 调整
.editorconfig配置 - 修正了部分语法高亮
- 调整了部分提示框的布局
- 调整
- 2023/03/04
- 新增了首次启动过程中对 SSH 连接警告信息的提示
- 新增了“权限拒绝”常见问题
- 调整了“克隆虚拟机”章节结构
- 调整了“常见问题”章节部分排版
- 2023/02/28
- 调整了部分信息框为默认收起
- 新增了“代理设置”页面的截图
- 新增了实验“成功的标志”章节
- 新增了“常见问题”板块
- 为部分操作增加了 ARM64 架构系统的特殊情况
- 2023/02/27
- 重新启用了底部导航
- 增加了针对深信服 Web VPN 导致的文本错误的缓解措施
- 增加了一定程度的反识别措施
- 小幅度的排版调整
- 2023/02/26
- 针对深信服 Web VPN 导致的文本错误添加了警告
- 2023/02/25
- 适配 Ubuntu 20.04 → 22.04 安装过程中变化
- 调整了软件下载部分的文本
- 重新制作了所有配图 抓飞友
- 2023/02/24
- 修复 Ubuntu Server 22.04 LTS 下载链接
- 2024/03/03
- 修复死链
- 更新了操作系统版本至 Ubuntu 22.04.4 LTS
- 更新了 Hadoop 版本至 3.3.6
- 2025/02/26
- 更新了操作系统版本至 Ubuntu 22.04.5 LTS
- 更新了 VMware Workstation Pro 以及 VMware Fusion 的下载方式
-
比如端口号等,目的是尽可能在后续实验中保持兼容性 ↩
-
如果你是 Windows 10 专业版、教育版或企业版,你可以使用 Hyper-V 功能来管理虚拟机,可以实现同样的效果,你也可以在 Windows 上使用 VirtualBox 来替代 VMware 或 Hyper-V. 如果你已经启用了 WSL 2(“适用于 Linux 的 Windows 子系统”),则你已经正在使用 Hyper-V 了 ↩
-
如果没有提示这个设置,可以忽略 ↩
-
理论上可以用
openjdk-8-jdk-headless来替换以消耗更小空间,但出于 Apache 软件的体量,使用完整版以避免特殊问题;经测试 Java 11 也可以正常运行 ↩ -
链接克隆可以大幅节约硬盘空间,在本教程实例中大约可以节约 10 GiB 空间。链接克隆功能只在 VMware Workstation Pro 提供 ↩↩
-
事实上,本实验已经有过在 Arch Linux 和 Fedora 上成功完成的经验了。你甚至可以在 AUR 上找到现有的包 ↩